Canal简介
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
学习
秉承着一切以官方文档为准的思想,先找Canal的官方github地址: https://github.com/alibaba/canal
Canal的官方文档非常优秀,对Canal的介绍全面而且清晰,学习canal完全够用了,这里主要记录一些实践的感悟和遇到的问题.
快速应用和API了解
搭建环境
本次实验在本机利用VMWare虚拟机搭建了CentOS7系统,安装了JDK(操作简单,不再讲了),然后安装了MySQL数据库和,具体的过程不再详细介绍,安装MySQL可以直接看博客(如果使用本地MySQL也是可以的,但是一般来说为了模拟真实环境,我还是习惯把MySQL装在虚拟机):
【centos7 + MySQL5.7 安装】centos7 安装MySQL5.7
值得注意的是,yum install mysql后还需要执行命令安装mariadb-server,两篇博客没有提到这点
1 | yum install -y mariadb-server |
给mysql设置初始密码时,如果密码过于简单,可能会有下面的提示:
1 | ERROR 1819 (HY000): Your password does not satisfy the current policy requirements |
MySQL中使用以下命令即可解决:
1 | set global validate_password_policy=0; |
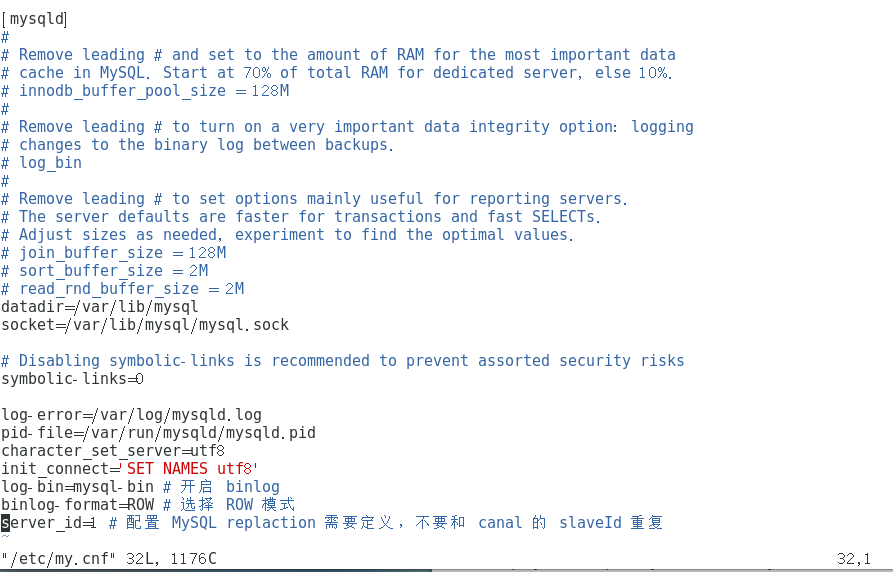
编辑mysql的my.cnf文件,命令: vim /etc/my.cnf
1 | [mysqld] |
然后开始下载Canal,在官方网址选合适的版本 https://github.com/alibaba/canal/releases ,使用wget下载解压即可.
值得注意的是,使用宿主机连接linux虚拟机的Canal时,务必打开防火墙的11111端口(Canal默认端口),命令如下:
1 | //开启端口 |
附上防火墙端口操作其他命令:
1 | //查询端口号11111是否开启: |
配置完毕后,就可以直接看官方文档进行后续操作了: https://github.com/alibaba/canal/wiki/QuickStart
关于MySQL的用户MySQL slave的权限,测试的时候我们可以直接用ROOT用户,它默认就有权限,其实不需要配置了.
这里我简单进行配置然后启动成功:
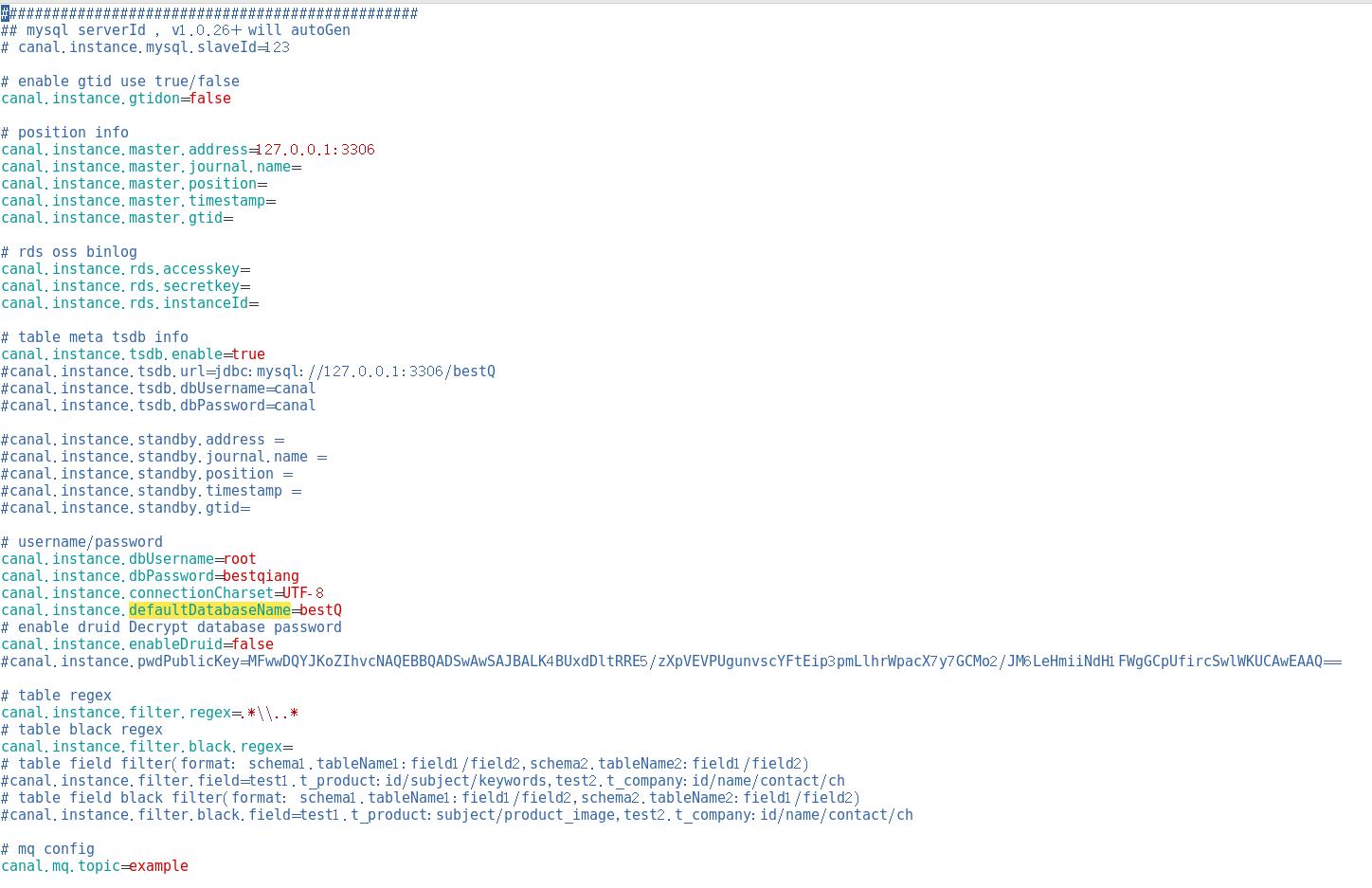
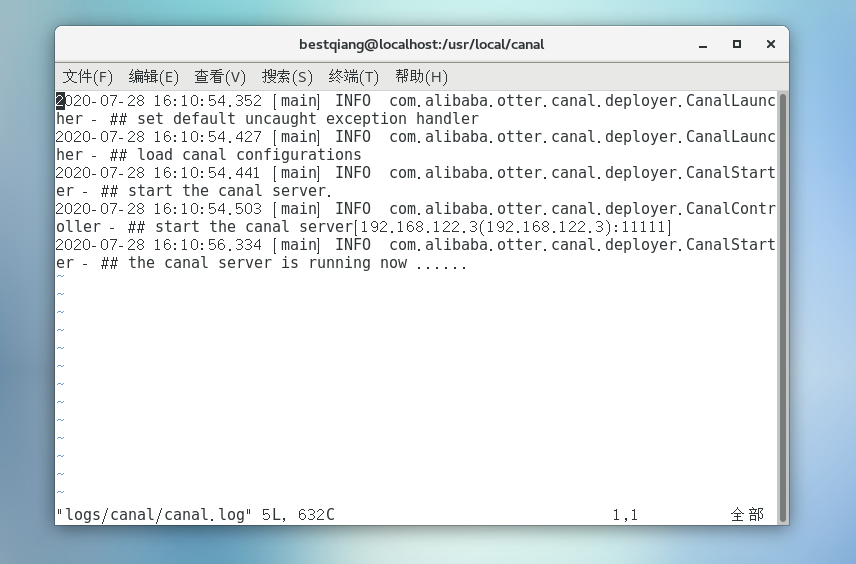
运行 ./bin/startup.sh 启动成功,可以查看日志:
Client API基本了解和连接Canal服务
建立maven工程,引入Canal的client包坐标:
1 | <dependency> |
按照官方的文档的目录ClientExample ,里面没有什么有价值的信息,跟着这个example去下载源码也看不太明白,少走弯路.可以直接点开ClientAPI,里面非常详细的介绍了
- canal client的类设计
- 流式API的异步响应模型
- 数据对象格式(protobuff高效格式)
- 基本使用的例子.
不得不说这文档写的很详细,而且有清晰有条理,看完后在下载源码进行阅读,看起来就轻松多了,下面是我写的一个测试用例(非HA模式,HA模式配置等看完下面两章配置以后,用Cluster进行连接就ok了),大家可以直接copy改一下地址在本地测试.
1 |
|
在程序运行后,用navicat连接数据库,在bestQ库:user表中插入两条信息:
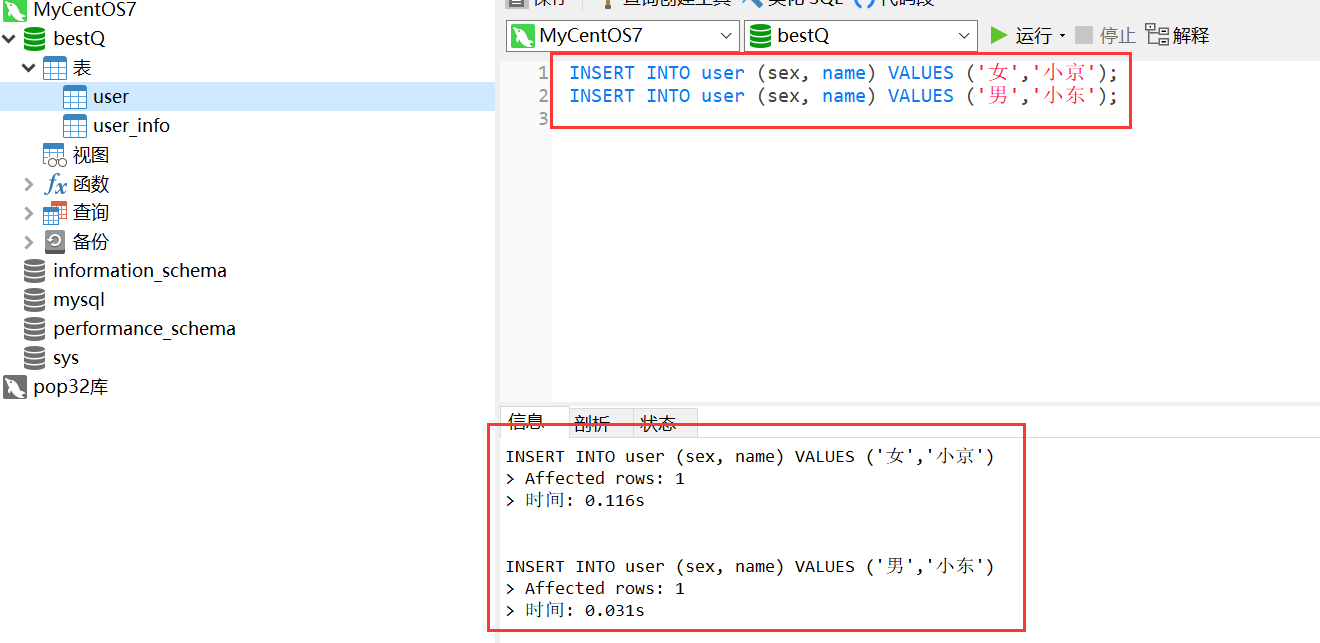
从打印结果可以看到,单机模式的client成功连接Canal Server,并获取了数据库增量信息:
1 | 2020-07-29 17:27:44.549 INFO [main] com.bestqiang.canal.CanalStudyTest:55 say: ================> 本次的的batchId为: 29 |
此外还有一个ClientAdapter是关于Canal的数据库同步功能,可以用于数据库之间的数据同步,主要将ETL的一些配置,有时间的话也可以试一下.
Canal管理页面和性能表现
对应页面 Canal Admin QuickStart 和 Canal Performance 以及它们的兄弟页面,这两章的介绍是关于Canal的WebUI操作界面管理和性能的一些测试评估的,写的挺详细的,可以都看一下了解一下怎么用,暂时不再做过多的讲解了,不作为重点.
Canal配置指南和整体设计
- 配置指南AdminGuide
- 整体设计DevGuide
这两章很重要!可以当作重点来看,由于官方文档比较详细优秀,所以直接看它就可以.
配置指南中主要介绍了几个关键点:
- 环境要求
- 部署和基本配置
- HA模式的配置
- MySQL多节点解析配置
整体设计中主要介绍了以下几个关键点:
- 产品整体设计
- 应用扩展方式
由于这本身就是由Java写的,所以说熟悉Java的小伙伴很了解配置方式了,可以参看下图,直接根据配置指南在spring的配置文件改就行了,其实就是配置一个Instance的Bean对象,使用PropertyPlaceholderConfigurer引入对应的properties文件配置的一些属性填进去:

附上配置加载的图,意思就是我们的instance可以通过Rpc/Http读取配置来启动(阿里那边内部的平台),也可以直接用本地Spring配置来启动,我们要使用一般就用它了(官网上这张图貌似崩了,这是从其他博客copy的):
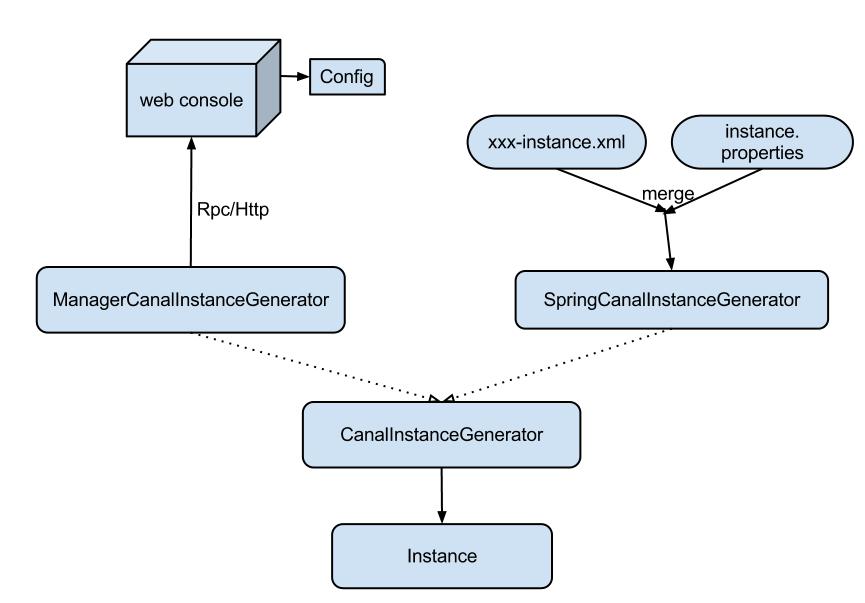
值得说明的是,配置指南看完后还不足以让使用者了解如何去配置.需要结合整体设计文章仔细看一下.
整体设计中描述了Instance子模块的
- eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
- eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
- eventStore: 数据存储 (可以存取在Memory, File, zk)
- metaManager: 增量订阅 & 消费信息管理器
其中eventSink模块有一句话这样说: 常见的 sink 业务有 1:n 和 n:1 形式,目前 GroupEventSink 主要是解决 n:1 的归并类业务
具体可以这样理解eventSink:
- 数据过滤:支持通配符的过滤模式,表名,字段内容等
- 数据路由/分发:解决1:n (1个parser对应多个store的模式)
- 数据归并:解决n:1 (多个parser对应1个store)
- 数据加工:在进入store之前进行额外的处理,比如join
1:n和n:1业务分别指的什么?
1 数据1:n业务 :
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在mysql上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。 所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注。
2 数据n:1业务:
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。 所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并.(参考了这个博客,也可以看看 https://www.cnblogs.com/yulu080808/p/8819260.html)
由于这是一个Java应用,所以我们可以直接在maven项目里把对应的canal.deployer的jar包引进来,对其中的maven依赖的版本如Spring,Zookeeper等可以进行自由升级,然后对配置文件进行覆盖,然后对项目进行改造,实现我们专属的Canal.其实我们也可以把Client和Server部署在一起,可以降低延迟,提高效率.
结语
这里主要梳理了Canal的大概学习步骤,主要还得去官方文档去学,我踩了一遍坑,把需要注意的点和学习顺序,以及自己的一些理解梳理了一下,注意实践和学习相结合,可以更好的理解Canal.

